 EN
EN CN
CN JP
JP


Press Releases
OPT DeepVision3 solves the problem of AI implementation
OPT DeepVision3 integrates a large visual basic model, which not only improves the robustness of the model, but also greatly shortens the cycle from training verification to deployment. It makes labeling interactions and various functional task operations more convenient, and solves the pain points of deep learning in the implementation during industrial production.
Efficient
AI model training is faster and smarter
How to reduce data dependence and labor costs, lower application thresholds, and shorten the total cycle has always been the primary problem hindering the widespread implementation of deep learning.
In order to overcome these challenges, DeepVision3 continues to optimize the underlying logic algorithm and achieves key technological innovations in incremental learning, small sample learning, model lightweighting, etc., significantly reducing the time cost of data collection, model training, and migration.
Faced with visual solutions with fewer defective samples, DeepVision3 uses small sample strategies such as data augmentation and algorithm enhancement to reduce the amount of data by 90%, from hundreds of pictures in the past to more than a dozen, and even a few pictures can complete AI Model training. A large number of high-quality training images are generated based on the deep image generation network, and the generation speed is increased by more than 3 times.
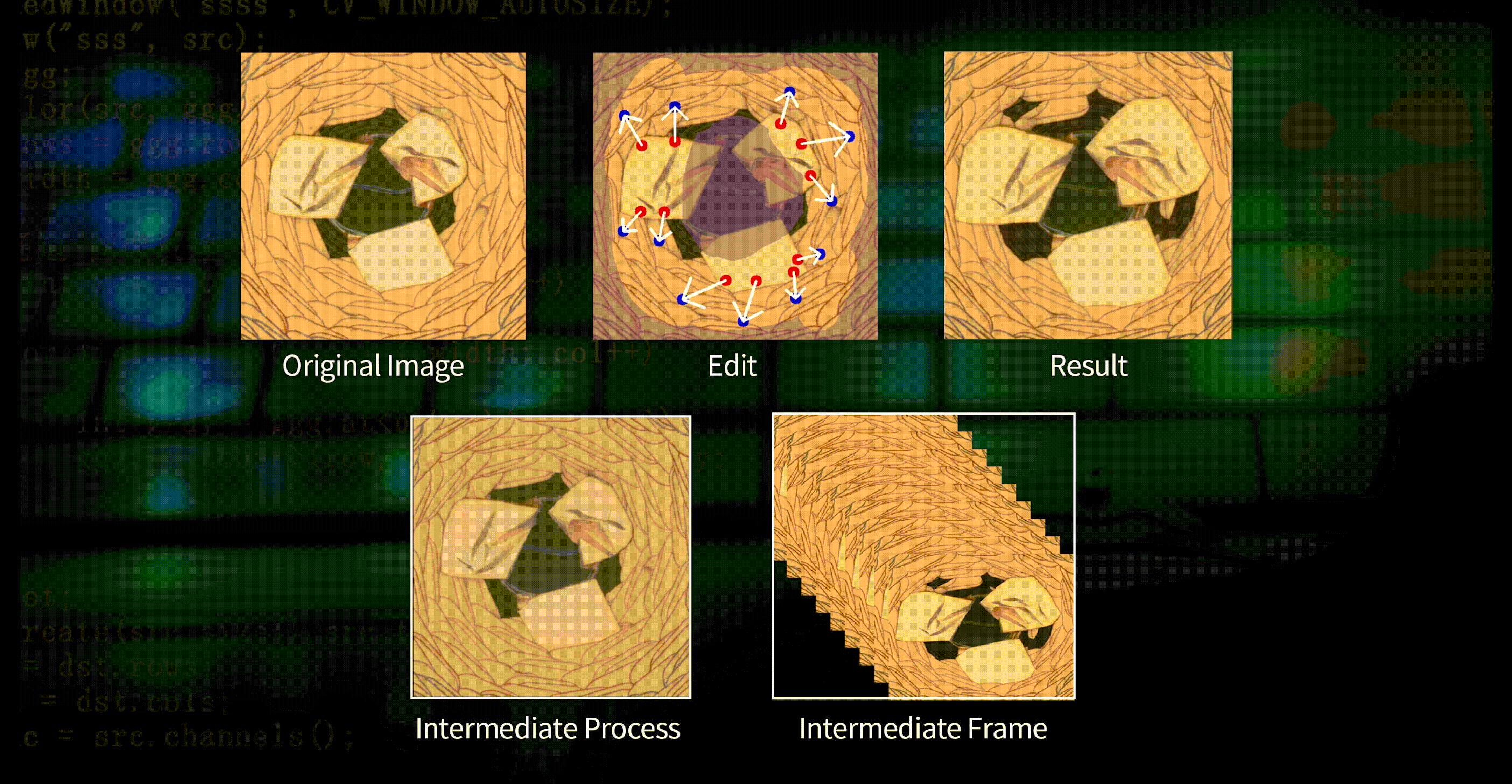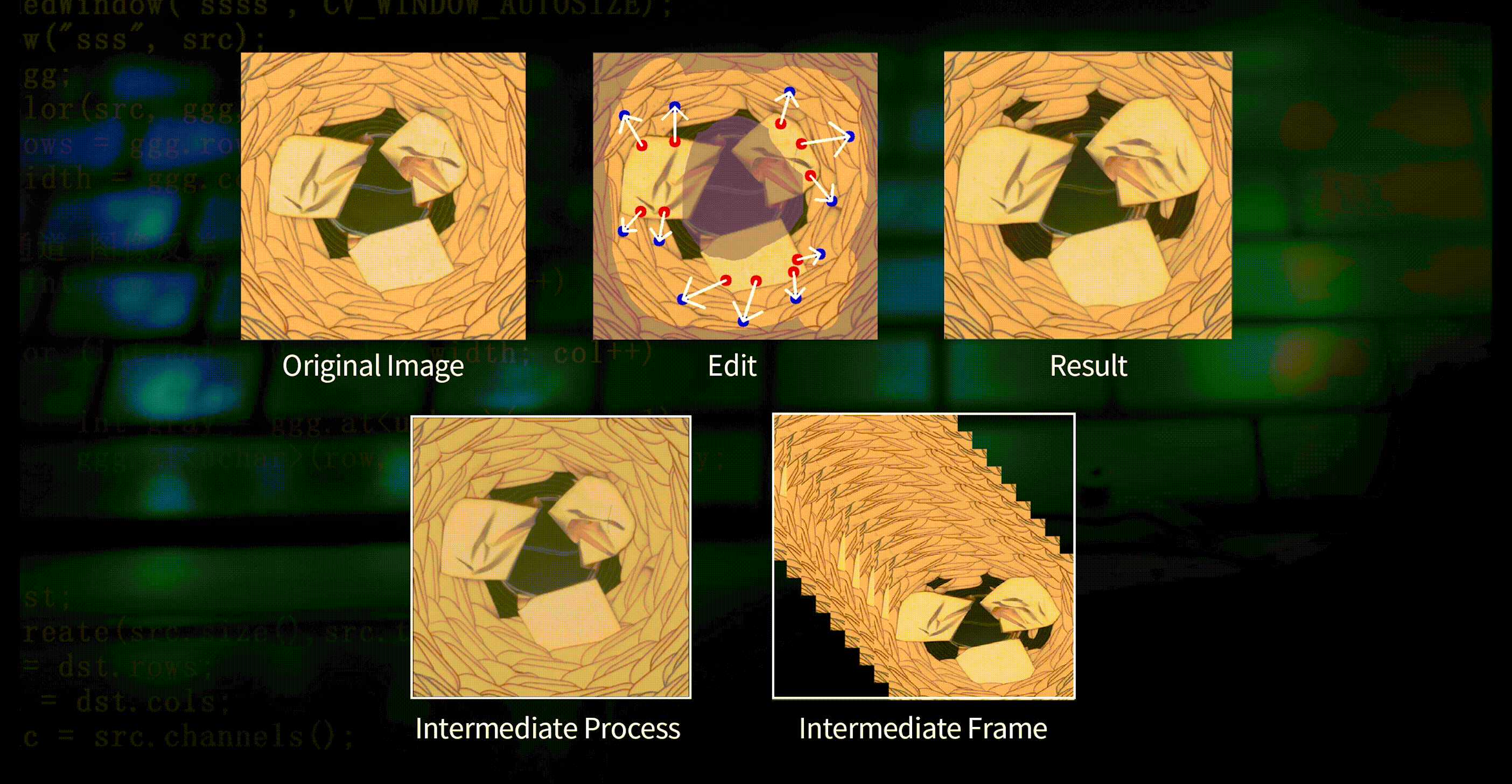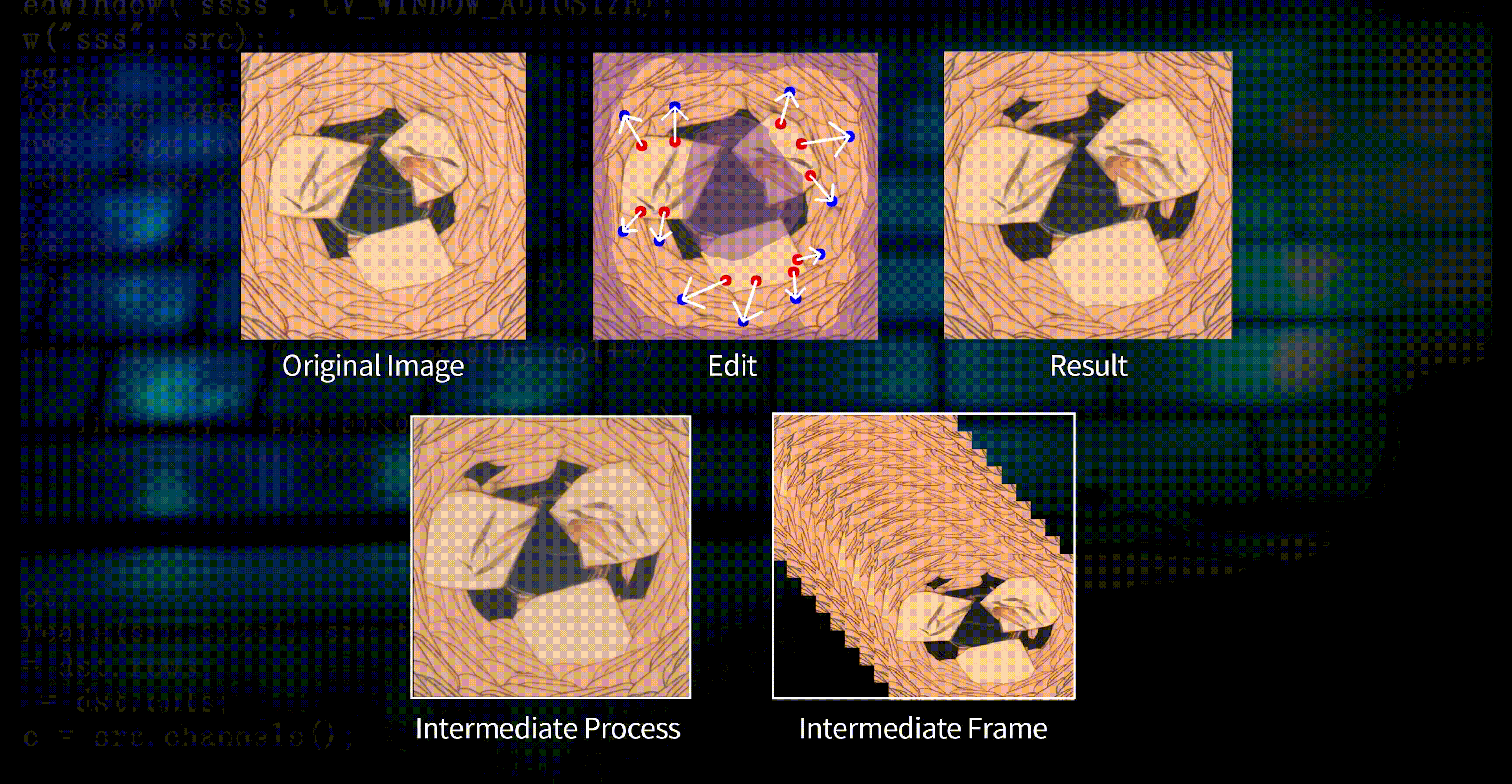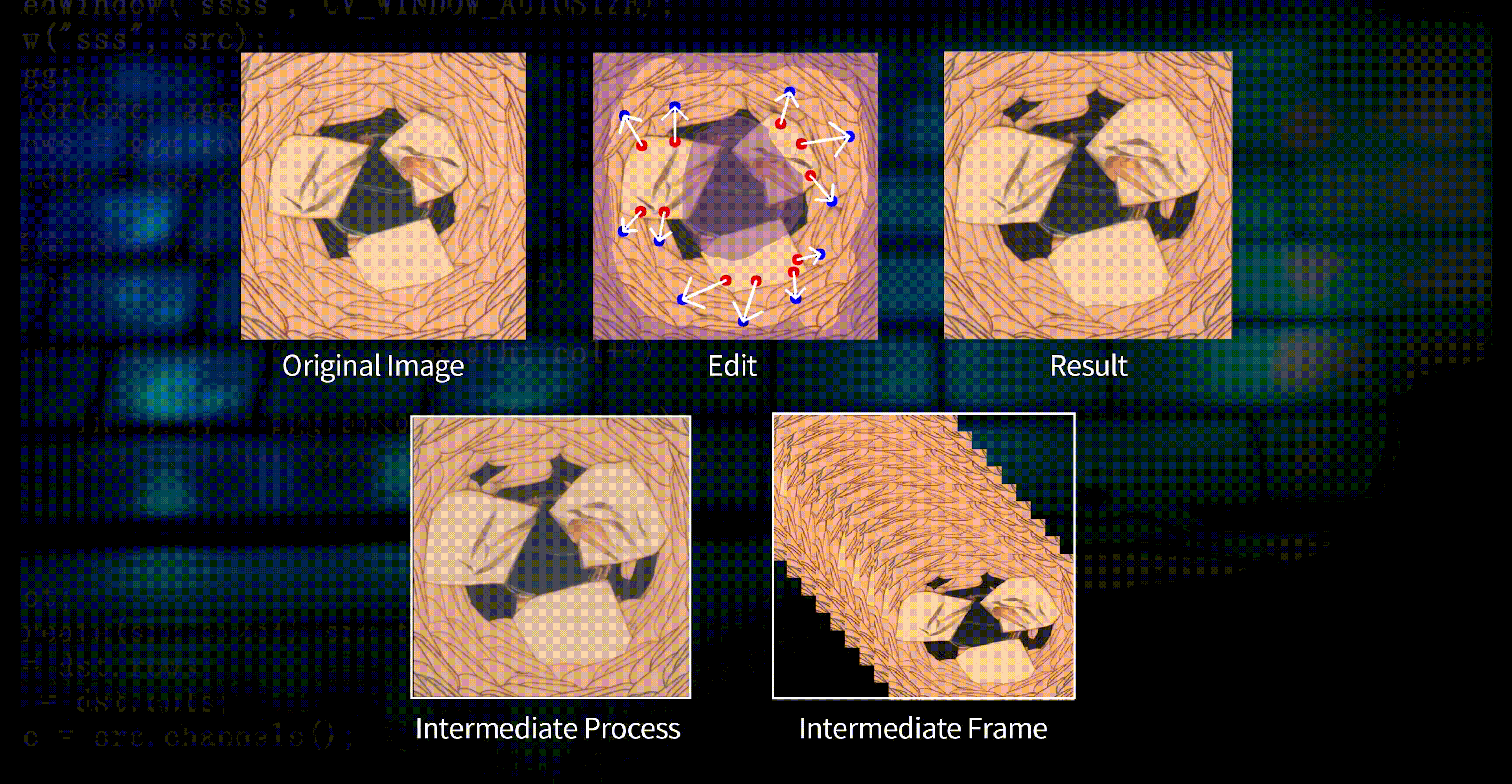
Under the premise that the model performance is almost unchanged, model training can be completed in 30 minutes for 4K-scale data; and to meet the application requirements of industrial scenarios better, DeepVision3 can achieve incremental training for new needs in just a few minutes.
In addition, DeepVision3 uses the lightweight strategy to not only reduce computing power requirements and reduce inference time, but more importantly, make model detection more accurate.
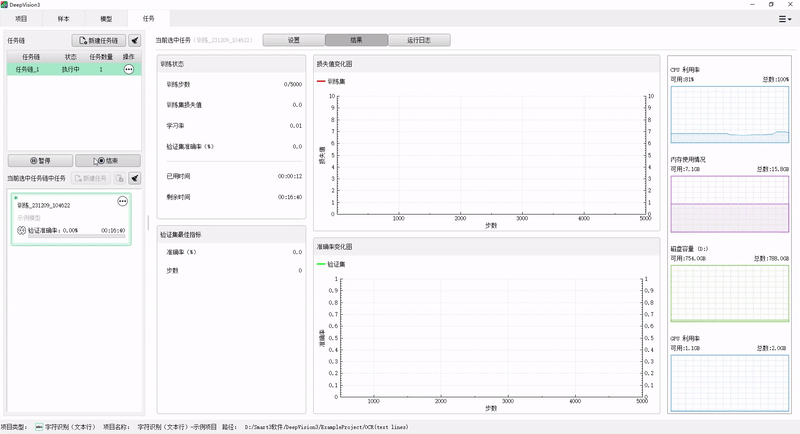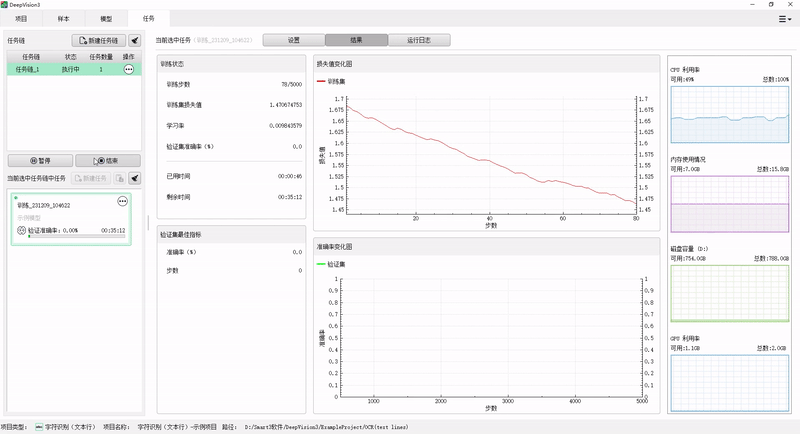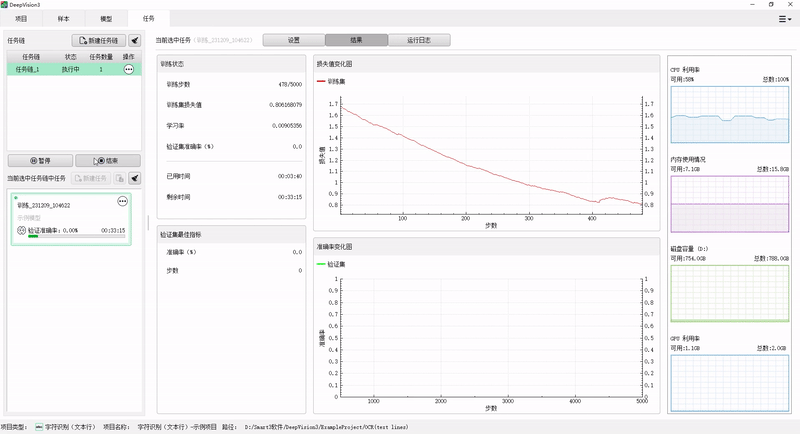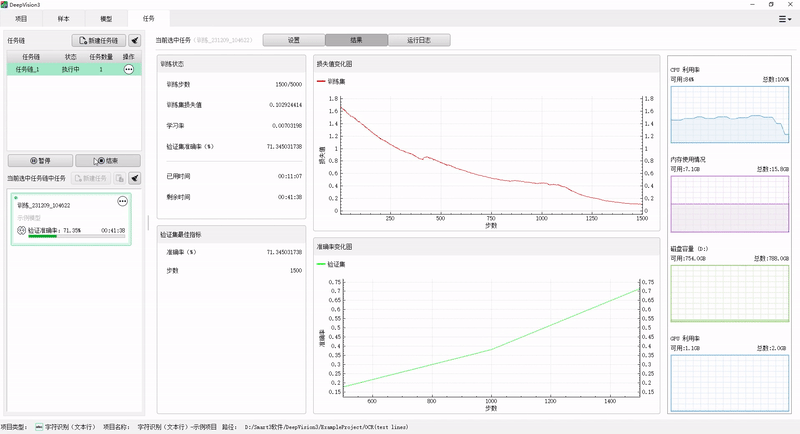
When using the CPU, 20-megapixel key target detection can be completed in about 60ms. Compared with conventional algorithms, the reasoning speed of detection and classification tasks is increased by more than 20 times.
Flexible
Integrated visual basic large model, consistent with factory model
While making the software more efficient, OPT also uses transfer learning, domain adaptation and other technologies to ensure that the trained model is more flexible and integrates generalization, versatility and flexibility.
Faced with quality inspections involving similar processes and the same process, DeepVision3 is based on one-click migration technology, or through adaptive fine-tuning, to achieve one-click model change. The training cycle can be shortened to a few hours, which solves the problem of large differences in defect shapes and frequent product model changes. The problem of poor generalization of the model caused by this.
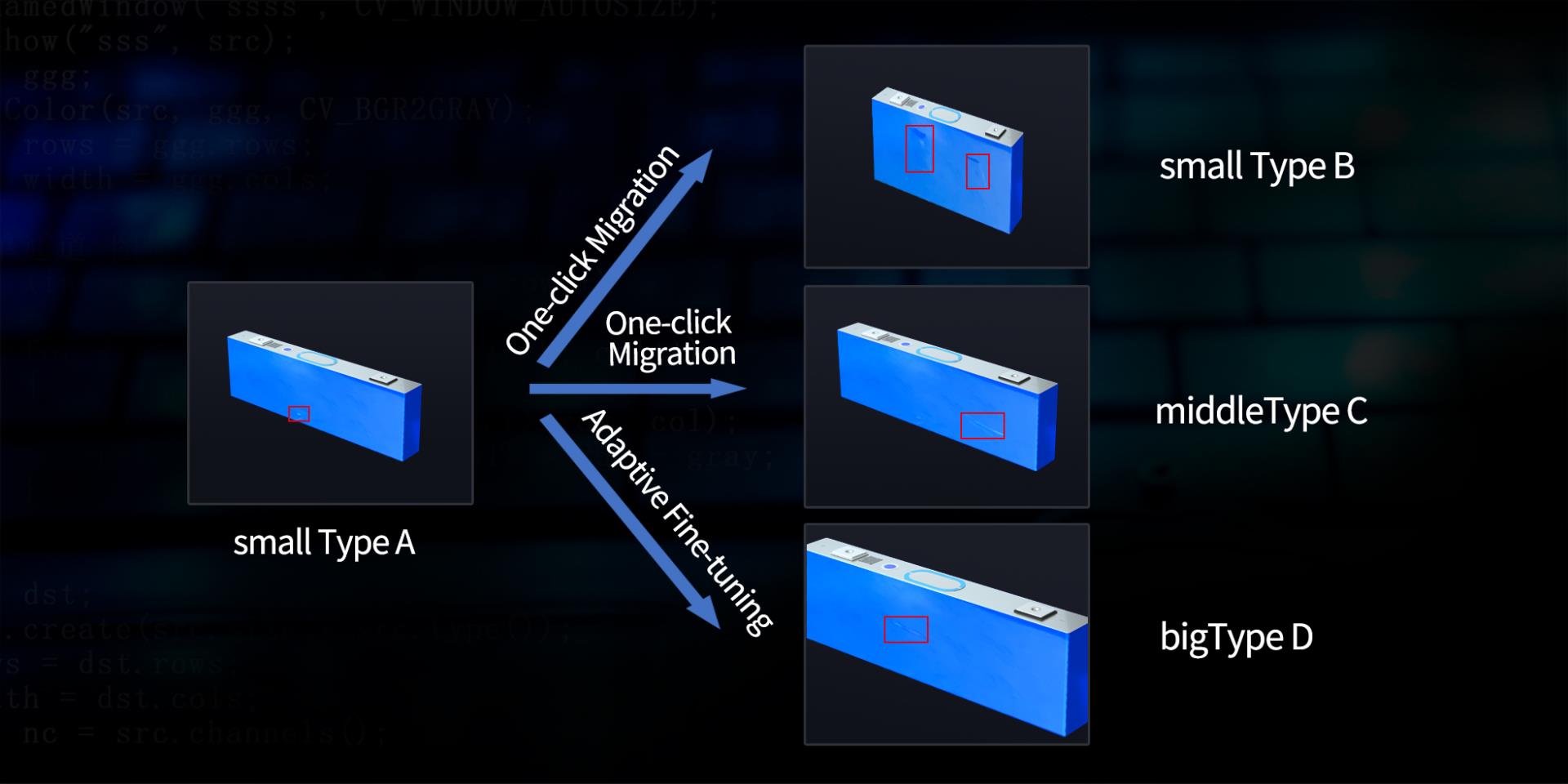
For the 3C and lithium battery industries, OPT has also developed a universal detection model. Defect detection in key processes can be used right out of the box. At the same time, the Zhixin large model will be launched soon to realize the positioning and detection of key objects with a new detection method. No model training is required, accelerating the widespread implementation of AI detection in more industries further. Moreover, DeepVision3 also supports global image management, multi-person collaboration, multi-process analysis, multi-machine collaboration and other functions, which is highly consistent with the existing factory generation model requirements.
Easy to use
Rich AI functions, one-click deployment
DeepVision3 covers a variety of task types such as semantic segmentation, character recognition, target detection, image classification, etc. It requires no programming and is highly easy to use, greatly reducing the cost of software learning.

DeepVision3 is equipped with a number of intelligent auxiliary annotation tools. For character recognition tasks, DeepVision3 has built-in universal OCR and centralized inspection functions to achieve semi-automatic annotation of characters. It can recognize characters in any direction or multiple lines of angled text, and users only need to check the results.

At the same time, for the most time-consuming semantic segmentation and labeling tasks, semantic segmentation AI tools, deep learning automatic labeling, traditional algorithm automatic labeling, contour extraction, etc. are integrated. Among them, the semantic segmentation AI tool only needs to click the mouse or pull a box to automatically generate high-precision and accurate pixel-level object annotations based on user points of interest, target boxes and mask information.
In addition, DeepVision3 also supports functions such as multi-label reuse and annotation quality control. During the model training process, tools such as hyperparameter setting prompts, process visualization, and evaluation result tracing are provided; it can also be deployed to Smart3 software with one click.





